Posts
-
Influence-based Attributions can be Manipulated
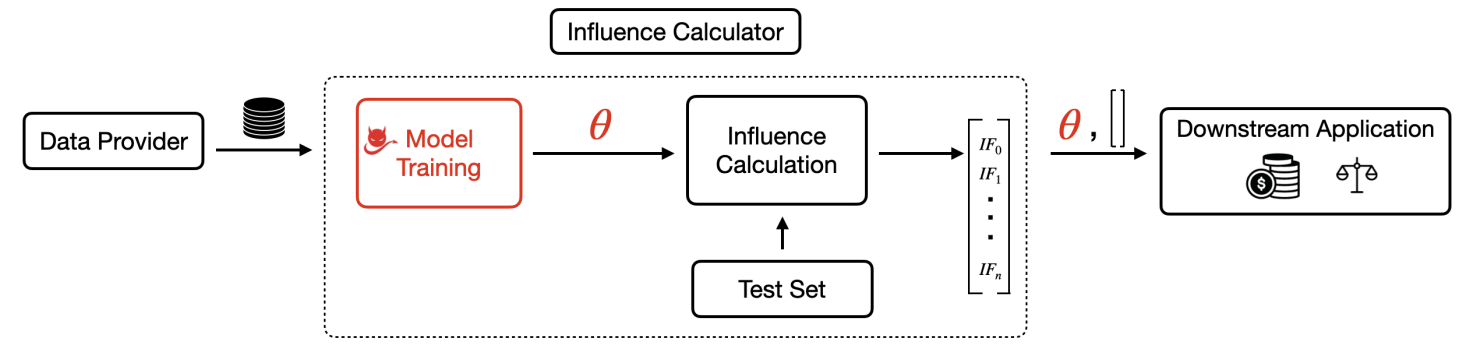
Threat Model. Data Provider provides training data. Influence Calculator trains a model and computes influence scores for the training data on the trained model and a test set. It outputs both the trained model and the resulting influence scores, which are used for a downstream application such as data valuation or fairness. Adversarial manipulation happens in the model training process, which trains a malicious model to achieve desired influence scores, while maintaining similar accuracy as the honest model.. -
FairProof : Confidential and Certifiable Fairness for Neural Networks
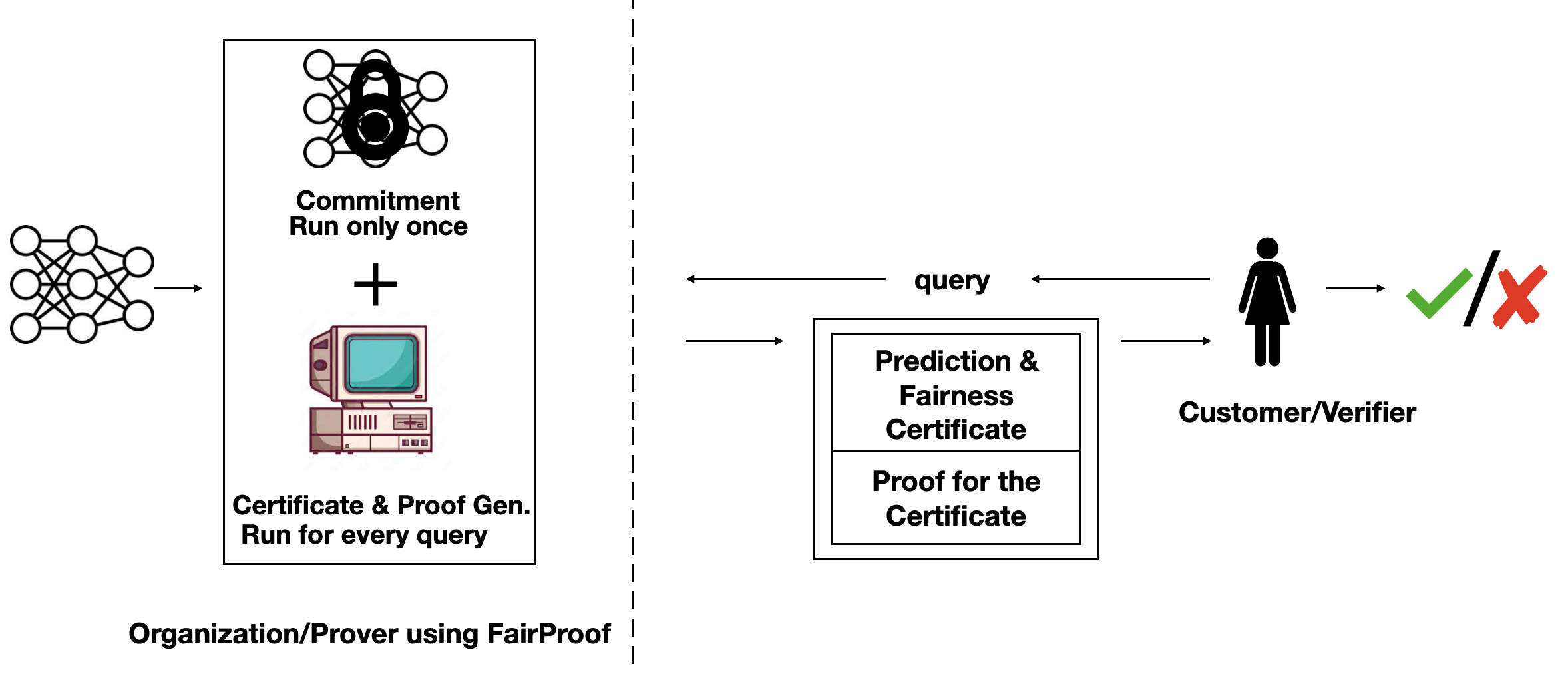
Setting of FairProof. Customer (which is also the verifier) submits a loan application to a bank (which is the prover). The bank uses a machine learning model to make decisions and responds with a decision, fairness certificate and a proof of the correct computation of this certificate. This proof is verified by customer. -
DYffusion: A Dynamics-informed Diffusion Model for Spatiotemporal Forecasting

DYffusion forecasts a sequence of $h$ snapshots $\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_h$ given the initial conditions $\mathbf{x}_0$ similarly to how standard diffusion models are used to sample from a distribution. -
How to Actively Learn in Bounded Memory
Machine learning practice is dominated by massive supervised algorithms, but gathering sufficient data for these methods can often prove intractable. Active learning is an adaptive technique for annotating large datasets in exponentially fewer queries by finding the most informative examples. Prior works on (worst-case) active learning often require holding the entire dataset in memory, but this can also prove difficult for the desired use-case of big data! In this post, we cover recent work towards characterizing bounded memory active learning, opening the door to applications in settings (e.g., learning on mobile devices) where one can't necessarily hope to store all of your data at once. -
Understanding Instance-based Interpretability of Variational Auto-Encoders
Instance-based interpretation methods, such as influence functions, have been widely studied for supervised learning methods as they help explain how black box neural networks predict. However, these interpretations remain ill-understood in the context of unsupervised learning. In this paper, we introduce VAE-TracIn, a computationally efficient and theoretically sound solution to investigate influence functions for variational auto-encoders (VAE). Our experiments reveal patterns about the impact of training data in VAE. -
Connecting Interpretability and Robustness in Decision Trees through Separation
Trustworthy machine learning (ML) has emerged as a crucial topic for the success of ML models. This post focuses on three fundamental properties of trustworthy ML models -- high accuracy, interpretability, and robustness. Building on ideas from ensemble learning, we construct a tree-based model that is guaranteed to be adversely robust, interpretable, and accurate on linearly separable data. Experiments confirm that our algorithm yields classifiers that are both interpretable, robust, and have high accuracy. -
Location Trace Privacy Under Conditional Priors
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a Renyi divergence based privacy framework, "Conditional Inferential Privacy", that quantifies this privacy risk given a class of priors on the correlation between locations. Additionally, we demonstrate an SDP-based mechanism for achieving this privacy under any Gaussian process prior. This framework both exemplifies why dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user’s trace. -
The Expressive Power of Normalizing Flow Models
Normalizing flows have received a great deal of recent attention as they allow flexible generative modeling as well as easy likelihood computation. However, there is little formal understanding of their representation power. In this work, we study some basic normalizing flows and show that (1) they may be highly expressive in one dimension, and (2) in higher dimensions their representation power may be limited. -
Explainable 2-means Clustering: Five Lines Proof
In a previous post, we discussed tree-based clustering and how to develop explainable clustering algorithms with provable guarantees. Now we will show why only one feature is enough to define a good 2-means clustering. And we will do it using only 5 inequalities (!) -
Explainable k-means Clustering
Popular algorithms for learning decision trees can be arbitrarily bad for clustering. We present a new algorithm for explainable clustering that has provable guarantees --- the Iterative Mistake Minimization (IMM) algorithm. This algorithm exhibits good results in practice. It's running time is comparable to KMeans implemented in sklearn. So our method gives you explanations basically for free. Our code is available on github. -
Towards Physics-informed Deep Learning for Turbulent Flow Prediction
While deep learning has shown tremendous success in a wide range of domains, it remains a grand challenge to incorporate physical principles in a systematic manner to the design, training, and inference of such models. In this paper, we aim to predict turbulent flow by learning its highly nonlinear dynamics from spatiotemporal velocity fields of large-scale fluid flow simulations of relevance to turbulence modeling and climate modeling. We adopt a hybrid approach by marrying two well-established turbulent flow simulation techniques with deep learning. Specifically, we introduce trainable spectral filters in a coupled model of Reynolds-averaged Navier-Stokes (RANS) and Large Eddy Simulation (LES), followed by a specialized U-net for prediction. Our approach, which we call turbulent-Flow Net (TF-Net), is grounded in a principled physics model, yet offers the flexibility of learned representations. We compare our model, TF-Net, with state-of-the-art baselines and observe significant reductions in error for predictions 60 frames ahead. Most importantly, our method predicts physical fields that obey desirable physical characteristics, such as conservation of mass, whilst faithfully emulating the turbulent kinetic energy field and spectrum, which are critical for accurate prediction of turbulent flows. -
How to Detect Data-Copying in Generative Models
What does it mean for a generative model to overfit? We formalize the notion of 'data-copying', when a generative model produces only slight variations of the training set and fails to express the diversity of the true distribution. To catch this form of overfitting, we propose a three-sample hypothesis test that is entirely model agnostic. Our experiments indicate that several standard tests condone data-copying, and contemporary generative models like VAEs and GANs can commit data-copying. -
The Power of Comparison: Reliable Active Learning
In the world of big data, large but costly to label datasets dominate many fields. Active learning, a semi-supervised alternative to the standard PAC-learning model, was introduced to explore whether adaptive labeling could learn concepts with exponentially fewer labeled samples. Unfortunately, it is well known that in standard models, active learning provides little improvement over passive learning for the foundational classes such as linear separators. We discuss how empowering the learner to compare points resolves not only this issue, but also allows us to build efficient algorithms which make no errors at all! -
Adversarial Robustness for Non-Parametric Classifiers
Adversarial robustness has received much attention recently. Prior defenses and attacks for non-parametric classifiers have been developed on a classifier-specific basis. In this post, we take a holistic view and present a defense and an attack algorithm that are applicable across many non-parametric classifiers. Our defense algorithm, adversarial pruning, works by preprocessing the dataset so the data is better separated. It can be interpreted as a finite sample approximation to the optimally robust classifier. The attack algorithm, region-based attack, works by decomposing the feature space into convex regions. We show that our defense and attack have good empirical performance over a range of datasets. -
Adversarial Robustness Through Local Lipschitzness
Robustness often leads to lower test accuracy, which is undesirable. We prove that (i) if the dataset is separated, then there always exists a robust and accurate classifier, and (ii) this classifier can be obtained by rounding a locally Lipschitz function. Empirically, we verify that popular datasets (MNIST, CIFAR-10, and ImageNet) are separated, and we show that neural networks with a small local Lipschitz constant indeed have high test accuracy and robustness.
subscribe via RSS