Location Trace Privacy Under Conditional Priors
Imagine a mobile app that repeatedly records your geolocation over a short period of time – say a day. We call this sequence of locations a location trace. Ideally, the app would like to use these locations to send recommendations or ads or even reminders. But there is the issue of privacy; many people including myself, would feel uncomfortable if our exact locations were to be shared with and recorded by apps. One option may be to completely shut off all location services. But is it possible to have a happy medium? In other words, can we obscure a location trace of an user while still providing some privacy?
Rigorous Privacy Definitions: Differential and Inferential
Before we get to what privacy means in this case, let us look at how rigorous privacy definitions work. Broadly speaking, the literature has two main philosophies of rigorous definitions of statistical privacy — differential and inferential privacy. Differential privacy is an elegant privacy definition designed by cryptographers Cynthia Dwork, Frank McSherry, Kobbi Nissim and Adam Smith in 2006. The philosophy here is that the participation of a single person in the data should not make a big difference to the probability of any outcome; this, in turn, implies that an adversary watching the output of a differentially private algorithm cannot determine for sure if a certain person is in the dataset or not. Differential privacy has many elegant properties — such as, robustness to auxiliary information, graceful composition and post processing invariance.
Inferential privacy in contrast means that an adversary with a certain prior knowledge does not gain a lot of extra knowledge after seeing the output of a private algorithm. While this notion is older than differential privacy, it was formalized by Kifer and Machanavajjhala in 2012 as the Pufferfish privacy framework. Inferential privacy does not always have the elegant properties of differential privacy, but it tends to be more flexible in the sense that it can obscure some specific events. Besides, some inferential privacy frameworks or algorithms do have graceful composition and are robust to certain kinds of auxiliary information. There is a no-free-lunch theorem that states that inferential privacy against all manner of auxiliary information will imply no utility — and so there is a limit to how far this can extend.
A Privacy Framework for Location Traces
Coming back to the privacy of location traces, let us now think about some options on how to model them in a rigorous privacy framework. There are two interesting aspects about location traces. First, location is continuous spatial data — and for both privacy and utility, we may need to obscure it up to a certain distance. We call this the spatiality aspect. But the more challenging aspect is correlation. My location at 10am is highly correlated with my location at 10:05, and not building this into a privacy framework may lead to privacy leaks.
Our first option is to use local differential privacy (LDP), which is basically differential privacy applied to a single person’s data. This will mean that two traces — one in New York and one in California — will be almost indistinguishable. However, this involves adding considerable noise to each trace — so much so as to render them completely useless. We will have very good privacy, but almost no utility whatsoever.
Our second option is to realize that while most people may be uncomfortable sharing fine-grained location information, they may be okay with coarse-grained data. For example, since I work at UCSD, which is in La Jolla, CA, I may not mind someone knowing that I spend most of my working hours in La Jolla; but I would not want them to know my precise location. This is known as geo-indistinguishability, and is achieved by adding independent noise with a radius $r$ to each location. This improves utility, if we are releasing a single location, but still has challenges with traces. If we average the private locations at 10am and 10:05am, then we get a better estimate since the underlying true locations are highly correlated.
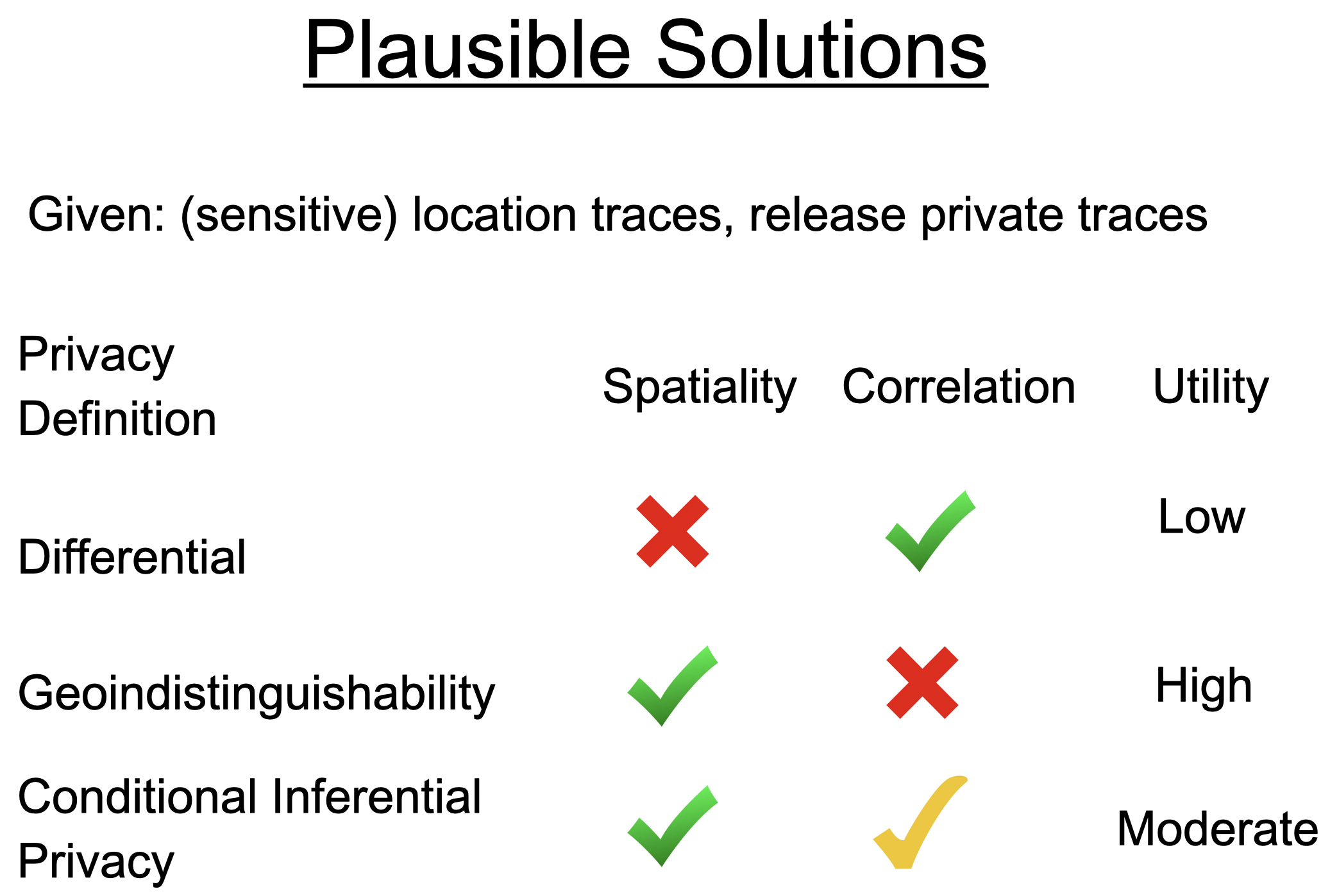
Tradeoffs of three privacy definitions for location data: While DP prevents use of correlation, it does not allow for utility with individual traces. Geoindistinguishability works well for a single location, but cannot prevent an adversary from correlating points close by in time. Our definition (conditional inferential privacy) provides an intermediate: prevent inference against a class of priors while still offering valuable utility.
Conditional Inferential Privacy
This brings us to our framework, Conditional Inferential Privacy (CIP). Here we aim to obscure each location to within a radius $r$, while taking into account correlation across time through a Gaussian Process prior. Gaussian processes effectively model a sequence of $n$ random variables as an $n$-dimensional vector drawn from a multivariate normal distribution (see Rasmussen Ch. 2 for more detail). In the location setting, the correlation between two locations increases with their proximity in time. Gaussian processes are frequently used to model trajectories (Chen ‘15, Liang & Hass ‘03, Liu ‘98, Kim ‘11), so this serves as a good model for a prior. Through directly modeling correlations, we can ensure that we can obscure locations up to a radius $r$, even in the presence of these correlations.
Formally, our framework builds upon the Pufferfish inferential privacy framework. We have a set of basic secrets $S$ consisting of events $s_{x,t}$, which denotes “User was at location $x$ at time $t$”. These are the kinds of events that we would like to hide. In practice, we may choose to hide more complicated events — such as “User was at home at 10am and at the coffee shop at 10:05am”; these are modeled by a set of compound events $C$, which is essentially a set of tuples of the form $(s_{x_1, t_1}, s_{x_2, t_2}, …)$.
We then have the set of secret pairs $P$ which is a subset of $C \times C$ — these are the pairs of secrets that the adversary should not be able to distinguish between. Finally we have a set of priors $\Theta$, which is a set of Gaussian processes that presumably represents the adversary’s prior.
A mechanism $M$ is said to follow $(P, \Theta)$-CIP with parameters $(\lambda, \epsilon)$, if for all $\theta \in \Theta$ and all tuples in $(s, s’) \in P$, we have that:
\[D_{\text{Renyi}, \lambda} \Big(\Pr(M(X) = Z | s, \theta ) , \Pr(M(X) = Z | s’, \theta)\Big) \leq \epsilon\]where $D_{\text{Renyi}, \lambda}$ is the Renyi divergence of order $\lambda$ (see Mironov ‘17 for background on Renyi divergence and its use in the privacy literature). Essentially what this means is that the distributions of the output of the mechanism $M$ are similar under the secret s and s’. Similar here means low Renyi divergence.
There are a couple of interesting things to note here. First, note that unlike differential privacy, here the privacy is over both the prior and the randomness in the mechanism; this is quite standard for inferential privacy. Second, observe that we use Renyi divergence in the definitions instead of the probability ratios or max divergence that is used in the standard differential privacy and Pufferfish privacy definition. This is because Renyi divergences have a natural synergy with Gaussians and Gaussian processes, which we use as our priors and mechanisms.
While not as elegant as differential privacy, this definition also has some good properties. We can show that we can get graceful decay of privacy for two trajectories of the same person from different time intervals — which is analogous to what is called parallel composition in the privacy literature. We also show that there is some robustness to side information. Details are in our paper.
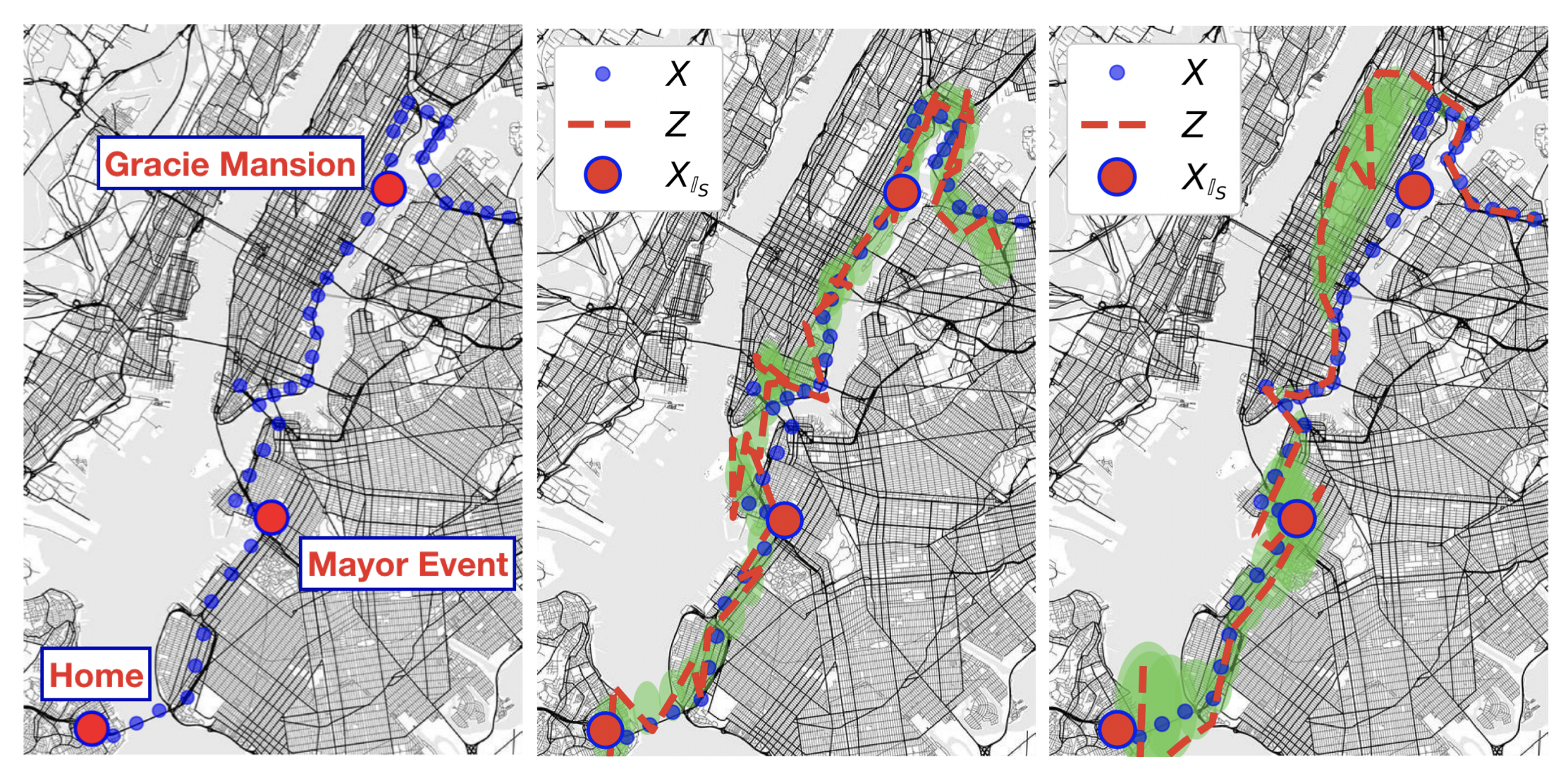
Example of how CIP maintains high uncertainty at secret locations (times). Left: a real location trace unknowningly collected from an NYC mayoral staff member by apps on their phone. The red dots indicate sensitive locations. Middle: demonstration of how Geoindistinguishability (adding independent isotropic gaussian noise to each location, as in the red trace) allows for high certainty of true location by correlation. The green envelope shows the posterior uncertainty of a Bayesian adversary with a Gaussian process prior (a GP adversary). Right: demonstration of how a CIP mechanism efficiently thwarts the same adversary's posterior at sensitive locations, given the same utility budget. The mechanism achieves this by both concentrating the noise budget near sensitive locations and by strategically correlating noise added.
Related Work
It is worth noting that we are in no way the first to attempt to offer meaningful location privacy. However, our method is distinguished in that it works in a continuous spatiotemporal domain, offers local privacy within a radius $r$ for sensitive locations, and has a semantically meaningful inferential guarantee. A mechanism offered by Bindschaedler & Shokri releases synthesized traces satisfying the notion of plausible deniability, but this is distinctly different from providing a radius of privacy in the local setting, as we do. Meanwhile, the frameworks proposed by Xiao & Xiong (2015) and Cao et al. (2019) nicely characterize the risk of inference in location traces, but use only first-order Markov models of correlation between points, do not offer a radius of indistinguishability as in this work, and are not suited to continuous-valued spatiotemporal traces.
Results
With the definition in place, we can now measure the privacy loss of different mechanisms. The most basic mechanism is to add zero-mean isotropic Gaussian noise with equal standard deviation to every location in the trace and publish the result; if the added noise has standard deviation $\sigma$, then we can calculate the privacy loss under CIP, as well as the mean square error utility. If a certain utility is desired, we can calibrate $\sigma$ to it and obtain a certain privacy loss.
A more sophisticated mechanism is to add zero-mean Gaussian noise with different covariances to locations at different time points. It turns out that we can choose the covariances to minimize privacy loss for a given utility, and this can be done by solving a Semi-Definite Program. The derivation and more details are in our paper.
We provide below a snap-shot of what our results look like. On the x-axis, we are plotting a measure of how correlated our prior is. If the prior is highly correlated, then it is easy to leak privacy for mechanisms that add noise — and hence correlated priors are worse for privacy. On the y-axis, we are plotting the posterior confidence interval size of the adversary — higher means higher privacy. Both mechanisms are calibrated to the same mean-square error, and hence the privacy-utility tradeoff is better if the y-axis is higher. From the figure, we see that our SDP-based mechanism does lead to a better privacy-utility tradeoff, and as expected, privacy offered declines as the correlations grow worse.
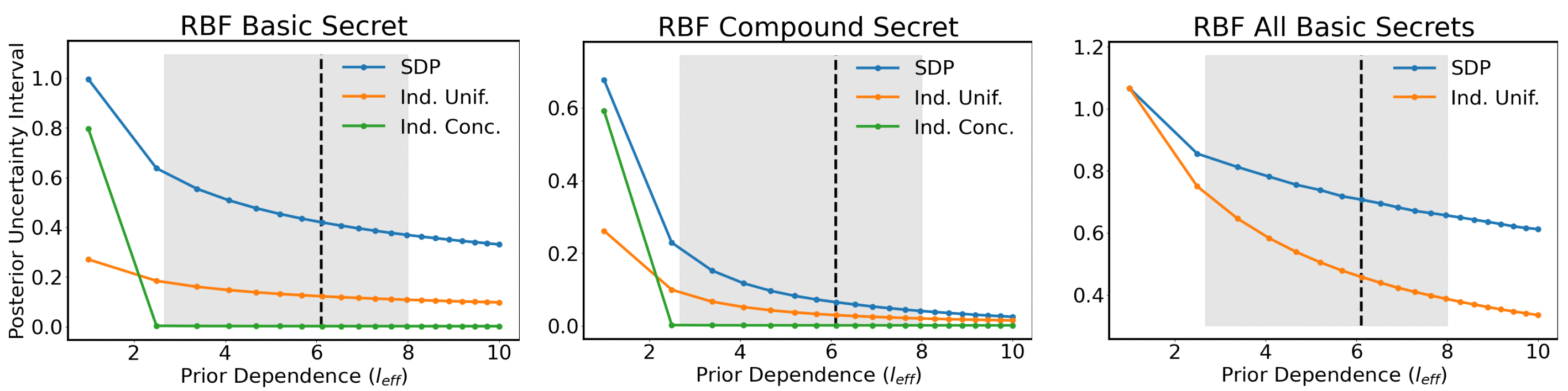
Our inferentially private mechanism (blue line) maintains higher posterior uncertainty for a Bayesian adversary with a Gaussian process prior (a GP adversary) as compared to two Geoindistinguishability-based baselines (orange and green). The x-axis indicates the degree of correlation anticipated by the GP adversary. The left panel shows the posterior uncertainty for a single basic secret. The middle panel shows uncertainty for a compound secret. The right panel shows posterior uncertainty when we design our mechanism to maintain privacy at every location (all basic secrets). The gray window shows a range of realistic degrees of dependence (correlation) gathered from human mobility data.

Examples of the noise covariance chosen by our mechanism: Each frame is a covariance matrix optimized by our SDP mechanism to thwart inference at either a single location basic secret or a compound secret of two locations. Noise drawn from a multivariate normal with this covariance is added along the 50 point trace. The two frames on the left show covariance chosen to thwart a GP prior with an RBF kernel. The two frames on the right show covariance chosen to thwart a GP prior with a periodic kernel.
Conclusion
In conclusion, we take a stab at a long-standing challenge in offering location privacy — temporal correlations — and we provide a way to model them cleanly and flexibly through Gaussian Process priors. This gives us a way to quantify the privacy loss for correlated location trajectories and devise new mechanisms for sanitizing them. Our experiments show that our mechanisms offer better privacy-accuracy tradeoffs than standard baselines.
There are many open problems, particularly in the space of mechanism design. Can we improve the privacy-utility tradeoff offered by our mechanisms through other means, such as subsampling the traces or interpolation? Can we make our definition and our methods more robust to side information? Finally, location traces are only one example of correlated and structured data; a remaining challenge is to build upon the methodology developed here to design privacy frameworks for more complex and structured data.